

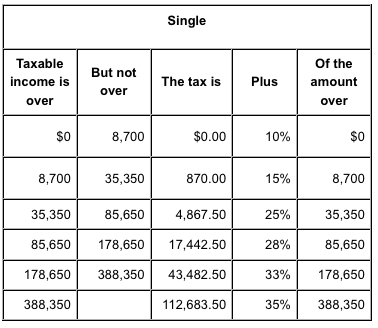
On the contrary, the association is negative i.e. -1 if the high y axis values tends to go with low values of x axis and considered as perfect negative correlation. Larger the correlation coefficient, stronger is the association. A weak correlation may be statistically significant if the numbers of observation are large. Correlation between the two variables does not necessarily suggest the cause and effect relationship.
In contrast, if one or more events are not independent but somehow influence the behavior of the next event, then you add the probabilities for each dependent event. In the case of the tossing of two coins this is a binomial equation problem and repeat tosses can be modeled by use of the Bernoulli distribution. In such trial, first problem is to find out the sample size. As discussed earlier, sample size can be calculated if we have S.D, minimum expected difference, alpha level, and power of study.

In statistical inference we make generalizations or estimates of population parameters based on sample statistics. If we were to compute the sample variance by taking the mean of the squared deviations and dividing by n we would consistently underestimate the true population variance. Dividing by (n-1) produces a better estimate of the population variance. The sample variance is nonetheless usually interpreted as the average squared deviation from the mean. When reporting summary statistics for a continuous variable, the convention is to report one more decimal place than the number of decimal places measured.
Population Mean
probability in biostatistics may be due to some direct relationship between two variables. This also may be due to some inherent factors common to both variables. The correlation is expressed in terms of coefficient.
A survival analysis of socio-demographic and clinical predictors … – BMC Infectious Diseases
A survival analysis of socio-demographic and clinical predictors ….
Posted: Wed, 22 Mar 2023 12:52:23 GMT [source]
Hence, SEM is not a descriptive statistics and should not be used as such. Correct use of SEM would be only to indicate precision of estimated mean of population. This class presents the fundamental probability and statistical concepts used in elementary data analysis. It will be taught at an introductory level for students with junior or senior college-level mathematical training including a working knowledge of calculus. A small amount of linear algebra and programming are useful for the class, but not required.
Discrete probability
Actually, there is a 67% chance — or a probability of 2/3 — of winning by switching, and only a 33% chance — or a probability of 1/3 — of winning by staying with the door that was originally chosen. The intuition of most people is that the chance of winning is equal whether we stay or switch — that there is a chance of winning with either selection. Often, relying only on our intuition is not enough to determine probability, so we’ll need some tools to work with, which is exactly what we’ll study in this section. The probability of the birth of a Downs syndrome baby is 1/800, but increases with age until by age 45, the chance is 1/12.

Once you have enrolled in a course, your application will be sent to the department for approval. You will receive an email notifying you of the department’s decision after the enrollment period closes. You can also check your application status in your mystanfordconnection account at any time. While you can only enroll in courses during open enrollment periods, you can complete your online application at any time. ProbabilityAn experiment is a process planed to obtain data.
Statistical method has two major branches mainly descriptive and inferential. After calculating sample size, next question is to apply suitable statistical test. If data are normally distributed, we should use parametric test otherwise apply non-parametric test. If we are comparing effects only after 12 weeks, then paired ‘t’ test can be applied for intra-group comparison and unpaired ‘t’ test for inter-group comparison. If we want to find out any difference between basic demographic data regarding gender ratio in each group, we will have to apply Chi-square test.
PROBABILITY
When comparison is made between two measurements in two different groups, unpaired ‘t’ test is used. For example, when we compare the effects of drug A and B (i.e. mean change in blood sugar) after one month from baseline in both groups, unpaired ‘t’ test’ is applicable. When comparison has to be made between two measurements in the same subjects after two consecutive treatments, paired ‘t’ test is used.
Strategies to inTerrupt RAbies Transmission for the Elimination Goal … – BMC Medicine
Strategies to inTerrupt RAbies Transmission for the Elimination Goal ….
Posted: Thu, 16 Mar 2023 07:00:00 GMT [source]
World’s Best PowerPoint Templates – CrystalGraphics offers more PowerPoint templates than anyone else in the world, with over 4 million to choose from. Winner of the Standing Ovation Award for “Best PowerPoint Templates” from Presentations Magazine. They’ll give your presentations a professional, memorable appearance – the kind of sophisticated look that today’s audiences expect. The characters which show variation are referred to as random variables or variates. In a bunch of 8 flowers, four are red and the others are white. Find out the probability that one flower drawn from the bunch at random is red, two flowers drawn from the bunch at random are of the same colour.
Systolic and diastolic blood pressures, total serum cholesterol and weight were measured to the nearest integer, therefore the summary statistics are reported to the nearest tenth place. Height was measured to the nearest quarter inch , therefore the summary statistics are reported to the nearest thousandths place. Body mass index was computed to the nearest tenths place, summary statistics are reported to the nearest hundredths place.
It may be noted that https://1investing.in/ I error can be made small by changing the level of significance and by increasing the size of sample. Confidence limits are two extremes of a measurement within which 95% observations would lie. These describe the limits within which 95% of the mean values if determined in similar experiments are likely to fall.
- Following are the different parametric test used in analysis of various types of data.
- This website includes study notes, research papers, essays, articles and other allied information submitted by visitors like YOU.
- Suppose we had three students and wished to select one of them randomly.
- Here the probability of rolling a “four” on a die in a single trial or p will be 1/6, because, the die has six faces.
Applying this, we are saving time, manpower, cost, and at the same time, increasing efficiency. Hence, an adequate sample size is of prime importance in biomedical studies. If sample size is too small, it will not give us valid results, and validity in such a case is questionable, and therefore, whole study will be a waste. Furthermore, large sample requires more cost and manpower.
In our course we will focus on Empirical probability and will often calculate probabilities from a sample usingrelative frequencies. There are many situations of interest in which physical circumstances do not make the probability obvious. In fact, most of the time it is impossible to find the theoretical probability, and we must use empirical probabilities instead. We are interested in the probability of an event — the likelihood of the event occurring. Suppose we had three students and wished to select one of them randomly.
However, when there are 3 or more sets of data to analyze, we need the help of well-designed and multi-talented method called as analysis of variance . In ANOVA, we draw assumption that each sample is randomly drawn from the normal population, and also they have same variance as that of population. It is a probability that study will reveal a difference between the groups if the difference actually exists. A more powerful study is required to pick up the higher chances of existing differences. Power is calculated by subtracting the beta error from 1.
This is useful in practice since theLaw of Large Numbersallows us to estimate the actual probability of an event by the relative frequency with which the event occurs in a long series of trials. We can collect this information as data and we can analyze this data using statistics. If we toss a coin, roll a die, or spin a spinner many times, we hardly ever achieve the exacttheoreticalprobabilities that we know we should get, but we can get pretty close. When we run a simulation or when we use a random sample and record the results, we are usingempiricalprobability. This is often called theRelative Frequencydefinition of probability.
Median is a better indicator of central value when one or more of the lowest or the highest observations are wide apart or are not evenly distributed. Median in case of even number of observations is taken arbitrary as an average of two middle values, and in case of odd number, the central value forms the median. Mode is the most frequent value, or it is the point of maximum concentration. Most fashionable number, which occurred repeatedly, contributes mode in a distribution of quantitative data . Mode is used when the values are widely varying and is rarely used in medical studies. For skewed distribution or samples where there is wide variation, mode, and median are useful.
Though this universe is full of uncertainty and variability, a large set of experimental/biological observations always tend towards a normal distribution. This unique behavior of data is the key to entire inferential statistics. In addition to the mean, the degree of variability of responses has to be indicated since the same mean may be obtained from different sets of values. Standard deviation describes the variability of the observation about the mean. To describe the scatter of the population, most useful measure of variability is SD.
This theorem states that the probability of two independent events occurring simultaneously is the product of individual probabilities of those events. Probability rules • Mutually excluded events • Two events are mutually excluded if the occurrence of an event avoid the occurrence of the other. • The probability of occurrence of two mutually excluded events, is the probability of occurrence of an event or another, and we can obtain the probability, add the individual probabilities of each event. Since we often rely on a single sample to estimate population parameters, we never actually know how good our estimates are. However, one can use sampling methods that reduce bias, and the degree of random error in a given sample can be estimated in order to get a sense of the precision of our estimates. The sample variance is not actually the mean of the squared deviations, because we divide by (n-1) instead of n.
- Many sporting events begin with a coin flip to determine which side of the field or court each team will play on, or which team will have control of the ball first.
- At least in principle the repeated tosses are independent so to find the probability you just multiply each event’s probability to get the total.
- Table 32.1 Probability of different combinations of head and tail of coin A and coin B tossed either simultaneously or separately.
- In practice, we will need to estimate the prevalence using a sample and in order to make inferences about the population from a sample, we will need to understand probability.
- Three different combinations of one head and two tails- .
You are about to undergo an intense and demanding immersion into the world of mathematical biostatistics. Over the next few weeks, you will learn about probability, expectations, conditional probabilities, distributions, confidence intervals, bootstrapping, binomial proportions, and much more. Module 1 covers experiments, probability, variables, mass functions, density functions, cumulative distribution functions, expectations, variations, and vectors. In binomial distribution (p+q)n, if the value of power n is infinite and all the frequency points are linked by a line on graph paper, a simple curved line will be obtained. That is called normal frequency distribution curve (Fig.32.1).
Leave a Reply